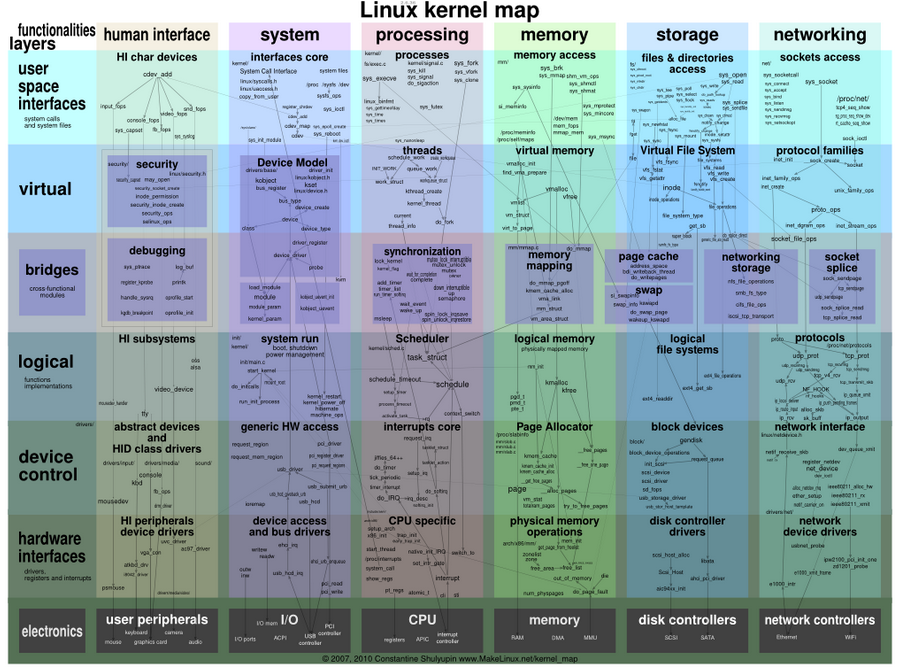
В этой статье мы рассмотрим язык программирования Python в качестве инструмента для получения различной информации о системе под управлением Linux.
Какой Python?
Когда я имею в виду Python, я имею в виду CPython 2 (2.7, если быть точным). Я буду говорить об этом явно, когда тот же код не будет работать с CPython 3 (3.3) и предоставлю альтернативный код вместе с объяснением различий. Просто чтобы убедиться, что у вас установлен CPython, наберите терминала python or python3, и вы должны увидеть приглашение Python, которое отобразиться в вашем терминале.
Обратите внимание, что если файл содержит первую строку вида #!/usr/bin/env python будут, то это означает, что мы хотим, чтобы интерпретатор Python мог выполнить этот файл. Следовательно, если вы сделаете свой скрипт исполняемым с помощью chmod +х script-name.py, вы можете выполнить его, используя команду ./script-name.py.
Исследуем модуль platform
Модуль platform из стандартной библиотеке имеет ряд функций, которые позволяют нам получать различную информацию о системе. Давайте запустим интерпретатор Python и изучим некоторые из них, начиная с функции platform.uname():
>>> import platform
>>> platform.uname()
('Linux', 'fedora.echorand', '3.7.4-204.fc18.x86_64', '#1 SMP Wed Jan 23 16:44:29 UTC 2013', 'x86_64')
Если вы знаете о команде uname в Linux, вам наверное уже стало ясно, что эта функция представляет собой своего рода интерфейс к этой команде. В Python 2, она возвращает кортеж, состоящий из типа системы (или типа ядра), имени хоста, версии, номера релиза и информации об аппаратных средствах и процессоре. Вы можете получить доступ к отдельным атрибутам с помощью индексов, например так:
>>> platform.uname()[0] 'Linux'
В Python 3, функция возвращает именованный кортеж:
>>> platform.uname() uname_result(system='Linux', node='fedora.echorand', release='3.7.4-204.fc18.x86_64', version='#1 SMP Wed Jan 23 16:44:29 UTC 2013', machine='x86_64', processor='x86_64')
Так как возвращаемый результат является именованным кортежем, это позволяет легко ссылаться на отдельные атрибуты по имени, вместо того, чтобы запоминать их индексы, например, вот так:
>>> platform.uname().system 'Linux'
Модуль platform также имеет интерфейсы прямого доступа для некоторых из указанных выше атрибутов, например, так:
>>> platform.system() 'Linux' >>> platform.release() '3.7.4-204.fc18.x86_64'
Функция linux_distribution() возвращает информацию о используемом вами дистрибутиые Linux. Например, в системе Fedora 18, эта команда возвращает следующую информацию:
>>> platform.linux_distribution()
('Fedora', '18', 'Spherical Cow')
Результат возвращается в виде кортежа, состоящего из названия дистрибутива, его версии и кодового именем. Дистрибутивы, поддерживаемые вашей конкретной версией Python, можно получить, распечатав значение атрибута _supported_dists:
>>> platform._supported_dists
('SuSE', 'debian', 'fedora', 'redhat', 'centos', 'mandrake',
'mandriva', 'rocks', 'slackware', 'yellowdog', 'gentoo',
'UnitedLinux', 'turbolinux')
Если ваш дистрибутив Linux не является одним из них (или производным от одного из них), то вы, вероятно, не увидите никакой полезной информации из приведенного выше вызова функции.
Последняя функция из модуля platform, которую мы рассмотрим, это функция architecture(). При вызове этой функции без каких-либо аргументов, она возвращает кортеж, состоящий из разрядности архитектуры системы и формата исполняемого файла Python. Например:
>>> platform.architecture()
('64bit', 'ELF')
На 32-битной системе Linux, вы увидите:
>>> platform.architecture()
('32bit', 'ELF')
Вы получите аналогичные результаты, если вы укажете какой-либо другой исполняемый файл в системе, например, так:
>>> platform.architecture(executable='/usr/bin/ls')
('64bit', 'ELF')
Рекомендуем вам изучить другие функции модуля platform, которые среди прочего, позволят вам найти текущую версию Python. Если вам интересно узнать, как этот модуль получает информацию, вы можете посмотреть файл Lib/platform.py в каталоге с исходным кодом Python.
Модули os и sys, также представляют интерес для извлечения определенной информации о системе, например используемый вашей системой порядок байтов (Endianness). Далее мы выйдем за пределы модулей стандартной библиотеки Python, чтобы изучить некоторые общие подходы к получению доступа к информации о системе Linux, доступной через файловые системы proc и sysfs. Следует отметить, что информация, представлемая через эти файловые системы будет варьироваться между различными аппаратными архитектурами и, следовательно, вы должны иметь это в виду при чтении этой статьи, а также при написание сценариев, которые пытаются извлечь информацию из файлов в этих файловых системах.
Получаем информацию о центральном процессоре
Файл /proc/cpuinfo содержит информацию о процессорах вашей системы. Например, вот Python-версия того, что должна сделать команда cat /proc/cpuinfo:
#! /usr/bin/env python
""" print out the /proc/cpuinfo
file
"""
from __future__ import print_function
with open('/proc/cpuinfo') as f:
for line in f:
print(line.rstrip('\n'))
Выполнив эту программы с помощью Python 2 или Python 3, вы должны увидеть на экране все содержимое файла /proc/cpuinfo (в приведенной выше программе, метод rstrip() удаляет завершающий символ новой строки в конце каждой из строк).
В следующем листинге используется метод startswith() для отображения моделей ваших процессоров:
#! /usr/bin/env python
""" Print the model of your
processing units
"""
from __future__ import print_function
with open('/proc/cpuinfo') as f:
for line in f:
# Ignore the blank line separating the information between
# details about two processing units
if line.strip():
if line.rstrip('\n').startswith('model name'):
model_name = line.rstrip('\n').split(':')[1]
print(model_name)
При запуске этой программы, вы должны увидеть имена моделей каждого из ваших процессоров. Например, вот что я вижу на своей машине:
Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz
Теперь мы знаем несколько способов определить архитектуру нашей системы. Если быть точным, оба эти подходы фактически определяют архитектуру ядра вашей системы. Так что, если ваш компьютер на самом деле ваша машина является 64-разрядной, но работает под управлением 32-битного ядра, то эти методы будут сообщать о вашей машине, как имеющей 32-разрядную архитектуру. Для того, чтобы найти истинную архитектуру машины, вы можете посмотреть на флаг lm в списке флагов в /proc/cpuinfo. Флаг lm присутствует только на компьютерах с 64-битной архитектурой. Следующая программа иллюстрирует этот подход:
#! /usr/bin/env python
""" Find the real bit architecture
"""
from __future__ import print_function
with open('/proc/cpuinfo') as f:
for line in f:
# Ignore the blank line separating the information between
# details about two processing units
if line.strip():
if line.rstrip('\n').startswith('flags') \
or line.rstrip('\n').startswith('Features'):
if 'lm' in line.rstrip('\n').split():
print('64-bit')
else:
print('32-bit')
Как мы видим, можно читать /proc/cpuinfo и использовать простые методы обработки текста для получения данных, котрые мы ищем. Для того, чтобы сделать эти данные более подходящими для использования в дальнейшем в других частях программиы, лучше сделать содержимое /proc/cpuinfo доступным в качестве стандартной структуры данных, например такой как dictionary. Идея проста: если вы видите содержимое этого файла, вы увидите, что для каждого процессора существует целый ряд пар ключ — значение (в предыдущем примере, мы выводили название модели процессора, здесь название модели можно использовать как ключ). Информация о различных процессорах отделена друг от друга пустой строкой. Несложно построить структуру dictionary, которая содержит данные о каждом из процессоров в качестве ключеа. Для каждого из этих ключей, значением будет вся информация о соответствующем процессоре в файле /proc/cpuinfo. Следующий листинг показывает, как вы можете сделать это.
#!/usr/bin/env/ python
"""
/proc/cpuinfo as a Python dict
"""
from __future__ import print_function
from collections import OrderedDict
import pprint
def cpuinfo():
''' Return the information in /proc/cpuinfo
as a dictionary in the following format:
cpu_info['proc0']={...}
cpu_info['proc1']={...}
'''
cpuinfo=OrderedDict()
procinfo=OrderedDict()
nprocs = 0
with open('/proc/cpuinfo') as f:
for line in f:
if not line.strip():
# end of one processor
cpuinfo['proc%s' % nprocs] = procinfo
nprocs=nprocs+1
# Reset
procinfo=OrderedDict()
else:
if len(line.split(':')) == 2:
procinfo[line.split(':')[0].strip()] = line.split(':')[1].strip()
else:
procinfo[line.split(':')[0].strip()] = ''
return cpuinfo
if __name__=='__main__':
cpuinfo = cpuinfo()
for processor in cpuinfo.keys():
print(cpuinfo[processor]['model name'])
Этот код использует OrderedDict (упорядоченный dictionary) вместо обычного dictionary, так что ключ и значения сохраняются в том порядке, в котором они находятся в файле. Следовательно, за данными о первом процессоре следуют данные о втором процессоре и так далее. Если вызвать эту функцию, она возвращает вам dictionary. Ключами dictionary является ифнормация о каждом из процессоров. Затем вы можете использовать выбрать информацию только об интересующих вас процессорах (как показано в блоке if __name__==’__main__’). Вышеприведенная программа при запуске будет еще раз выводить название модели каждого из процессоров (это выполняется с помощью команды print(cpuinfo[processor][‘model name’]):
Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz Intel(R) Core(TM) i7-3520M CPU @ 2.90GHz
Информация о состоянии памяти
Аналогично /proc/cpuinfo, файл /proc/meminfo содержит информацию об оперативной памяти вашего компьютера. Следующая программа создает dictionary из содержимого этого файла и выводит его на экран:
#!/usr/bin/env python
from __future__ import print_function
from collections import OrderedDict
def meminfo():
''' Return the information in /proc/meminfo
as a dictionary '''
meminfo=OrderedDict()
with open('/proc/meminfo') as f:
for line in f:
meminfo[line.split(':')[0]] = line.split(':')[1].strip()
return meminfo
if __name__=='__main__':
#print(meminfo())
meminfo = meminfo()
print('Total memory: {0}'.format(meminfo['MemTotal']))
print('Free memory: {0}'.format(meminfo['MemFree']))
Как и раньше, вы можете также получить доступ к какой-либо конкретной информации, которую вы ищете, используя ее в качестве ключа (как показано в блоке if __name__==__main__ ). При выполнении программы, вы должны увидеть вывод, аналогичный следующему:
Total memory: 7897012 kB Free memory: 249508 kB
Сетевая статистика
Сейчас мы посмотрим, какую минформацию можно получить о сетевых устройствах нашей системы. Мы попробуем получить список сетевых интерфейсов системы и количество байт, переданных и полученных ими с момента последней перезагрузки системы. Файл /proc/net/dev поможет нам получить эту информацию. Если изучить содержимое этого файла, то вы заметите, что первые две строки содержат заголовок — т.е. первый столбец этого файла является имя сетевого интерфейса, второй и третий столбцы отображают информацию о количестве принятых и переданных байт (такую как общее количество отправленных байт, количество пакетов, ошибок и т.п.). Нам необходимо извлечь общий объем данных, переданных и принятых различными сетевыми интерфейсами. Следующий листинг показывает, как мы можем извлечь эту информацию из файла /proc/net/dev:
#!/usr/bin/env python
from __future__ import print_function
from collections import namedtuple
def netdevs():
''' RX and TX bytes for each of the network devices '''
with open('/proc/net/dev') as f:
net_dump = f.readlines()
device_data={}
data = namedtuple('data',['rx','tx'])
for line in net_dump[2:]:
line = line.split(':')
if line[0].strip() != 'lo':
device_data[line[0].strip()] = data(float(line[1].split()[0])/(1024.0*1024.0),
float(line[1].split()[8])/(1024.0*1024.0))
return device_data
if __name__=='__main__':
netdevs = netdevs()
for dev in netdevs.keys():
print('{0}: {1} MiB {2} MiB'.format(dev, netdevs[dev].rx, netdevs[dev].tx))
Запустив вышеприведенную программу, мы увидим список сетевых интерфейсов наряду с общим поличество полученных и переданных данных в MiB с момента последней перезагрузки системы, см. ниже:
em1: 0.0 MiB 0.0 MiB wlan0: 2651.40951061 MiB 183.173976898 MiB
В качестве упражнения, вы могли бы добавить в программу какой-либо механизмом персистентного хранения данных, чтобы получить собственную программу мониторинга использования сетевого канала.
Процессы
Каталог /proc содержит директории для каждого из запущенных в системе процессов. Имена этих каталогов такие же, как идентификаторы процессов для этих процессов. Следовательно, при сканировании каталога /proc, собрать список всех его подкаталогов, имена которых содержат только цифры, вы получите список идентификаторы всех запущенных в системе процессов. Функция process_list() в следующем листинге возвращает список с идентификаторов всех запущенных процессов. Длина этого списка будет равна общему количеству процессов, запущенных в системе. См. следующий листинг:
#!/usr/bin/env python
"""
List of all process IDs currently active
"""
from __future__ import print_function
import os
def process_list():
pids = []
for subdir in os.listdir('/proc'):
if subdir.isdigit():
pids.append(subdir)
return pids
if __name__=='__main__':
pids = process_list()
print('Total number of running processes:: {0}'.format(len(pids)))
Приведенная выше программа при выполнении покажет результат, похожий на следующий:
Total number of running processes:: 229
Каждый из каталогов процессов содержит ряд других файлов и подкаталогов, которые, в свою очередь, содержат различную информацию о командной строке запущенного процесса, совместно используемых библиотеках, используемых процессом и много другой информации.
Блочные устройства
Следующая программа выводит список всех блочных устройств путем чтения из виртуальной файловой системы sysfs. Блочные устройства в вашей системе можно найти в директории /sys/block. Таким образом, в вашей системы могут быть такие каталоги как /sys/block/sda, /sys/block/sdb и т. д. Для того, чтобы найти все такие устройства, мы выполняем сканирование каталога /sys/block с помощью простого регулярного выражения для выражения.
#!/usr/bin/env python
"""
Read block device data from sysfs
"""
from __future__ import print_function
import glob
import re
import os
# Add any other device pattern to read from
dev_pattern = ['sd.*','mmcblk*']
def size(device):
nr_sectors = open(device+'/size').read().rstrip('\n')
sect_size = open(device+'/queue/hw_sector_size').read().rstrip('\n')
# The sect_size is in bytes, so we convert it to GiB and then send it back
return (float(nr_sectors)*float(sect_size))/(1024.0*1024.0*1024.0)
def detect_devs():
for device in glob.glob('/sys/block/*'):
for pattern in dev_pattern:
if re.compile(pattern).match(os.path.basename(device)):
print('Device:: {0}, Size:: {1} GiB'.format(device, size(device)))
if __name__=='__main__':
detect_devs()
Запустив эту программу, вы увидите результат, похожий на следующий:
Device:: /sys/block/sda, Size:: 465.761741638 GiB Device:: /sys/block/mmcblk0, Size:: 3.70703125 GiB
Когда я запустил эту программу, у меня была подключена карта памяти SD, и, следовательно, вы можете видеть, что программа обнаружила ее. Вы можете расширить эту программу для распознавания других блочных устройств (например, виртуальных жестких дисков).
Пишем утилиты командной строки
Все утилиты командной строки Linux объединяет один общий момент — они позволяют пользователю указать аргументы командной строки, чтобы настроить поведение программы по умолчанию. Модуль argparse позволяет вашей программе иметь интерфейс, похожий на интерфейс системных утилит Linux. Следующий листинг показывает программу, которая ищет имена всех пользователей в системе и выводит для каждого из них имя shell’а (с использованием стандартного библиотечного модуля pwd):
#!/usr/bin/env python
"""
Print all the users and their login shells
"""
from __future__ import print_function
import pwd
# Get the users from /etc/passwd
def getusers():
users = pwd.getpwall()
for user in users:
print('{0}:{1}'.format(user.pw_name, user.pw_shell))
if __name__=='__main__':
getusers()
Запустив вышеприведенную программу, вы увидите всех пользователи вашей системы и имена их shell’ов.
Теперь, допустим, мы хотим чтобы пользователь программы имел возможность выбрать, хочет ли он видеть аккаунты, используемые системой для запуска демонов (например, для запуска Apache). Далее демонстрируется использование модуля argparse для реализации этой функции в путем дработки программы из предыдущего листинга:
#!/usr/bin/env python
"""
Utility to play around with users and passwords on a Linux system
"""
from __future__ import print_function
import pwd
import argparse
import os
def read_login_defs():
uid_min = None
uid_max = None
if os.path.exists('/etc/login.defs'):
with open('/etc/login.defs') as f:
login_data = f.readlines()
for line in login_data:
if line.startswith('UID_MIN'):
uid_min = int(line.split()[1].strip())
if line.startswith('UID_MAX'):
uid_max = int(line.split()[1].strip())
return uid_min, uid_max
# Get the users from /etc/passwd
def getusers(no_system=False):
uid_min, uid_max = read_login_defs()
if uid_min is None:
uid_min = 1000
if uid_max is None:
uid_max = 60000
users = pwd.getpwall()
for user in users:
if no_system:
if user.pw_uid >= uid_min and user.pw_uid <= uid_max:
print('{0}:{1}'.format(user.pw_name, user.pw_shell))
else:
print('{0}:{1}'.format(user.pw_name, user.pw_shell))
if __name__=='__main__':
parser = argparse.ArgumentParser(description='User/Password Utility')
parser.add_argument('--no-system', action='store_true',dest='no_system',
default = False, help='Specify to omit system users')
args = parser.parse_args()
getusers(args.no_system)
Выполненив эту программы с опцией --help, вы увидите подсказку с доступными для программы опциями (и описанием того, что эти опции делают):
$ ./getusers.py --help usage: getusers.py [-h] [--no-system] User/Password Utility optional arguments: -h, --help show this help message and exit --no-system Specify to omit system users
Пример вызова приведенной выше программы выглядит следующим образом:
$ ./getusers.py --no-system gene:/bin/bash
Если вы передаете неверный параметр, программа выведет сообщение об ошибке:
$ ./getusers.py --param usage: getusers.py [-h] [--no-system] getusers.py: error: unrecognized arguments: --param
Давайте попытаемся понять, как мы использовали модуль argparse в вышеприведенной программе. Оператор: parser = argparse.ArgumentParser(description='User/Password Utility') создает новый объект ArgumentParser с дополнительным описанием того, что эта программа делает.
Затем, мы добавляем аргументы, которые наша программа должна понимать, с помощью метода add_argument() в следующем операторе: parser.add_argument('--no-system', action='store_true', dest='no_system', default = False, help='Specify to omit system users'). Первый аргумент этого метода является именем параметра, котороый пользователь программы будет указывать в качестве аргумента командной строки при вызове программы, следующий параметр action=store_true указывает на то, что это булевское значение. То есть, на поведение программы влияет его наличие или отсутствие. Параметр dest определяет переменную, значение которой будет содержать значение переданной в параметер командной строки. Если этот параметр не указан пользователем, значением по умолчанию будет False, что указывает default = False. Последний параметр (help) - это сообщение, которое отображается, когда программа выводит информацию об этом параметре командной строки. Наконец, обработка аргументов происходит с использованием метода parse_args(), см: args = parser.parse_args(). После того, как парсинг параметров закончен, значения параметров, предоставленных пользователем, могут быть получены с помощью синтаксиса args.option_dest. В данном случае option_dest - это переменная, указанная в параметре dest метода add_argument(). Инструкция getusers(args.no_system) - это вызов функции getusers() со значением входного параметра взятым из переменной no_system (она, как мы помним, хранит значение, переданное пользователем в командной строке).
Следующая программа показывает, как можно определить небулевские параметры командной строки. Эта программа представляет собой переписанный код программы, выводящей список сетевых интерфейсов, в которую добавлена возможность указать интересующий вас сетевой интерфейс.
#!/usr/bin/env python
from __future__ import print_function
from collections import namedtuple
import argparse
def netdevs(iface=None):
''' RX and TX bytes for each of the network devices '''
with open('/proc/net/dev') as f:
net_dump = f.readlines()
device_data={}
data = namedtuple('data',['rx','tx'])
for line in net_dump[2:]:
line = line.split(':')
if not iface:
if line[0].strip() != 'lo':
device_data[line[0].strip()] = data(float(line[1].split()[0])/(1024.0*1024.0),
float(line[1].split()[8])/(1024.0*1024.0))
else:
if line[0].strip() == iface:
device_data[line[0].strip()] = data(float(line[1].split()[0])/(1024.0*1024.0),
float(line[1].split()[8])/(1024.0*1024.0))
return device_data
if __name__=='__main__':
parser = argparse.ArgumentParser(description='Network Interface Usage Monitor')
parser.add_argument('-i','--interface', dest='iface',
help='Network interface')
args = parser.parse_args()
netdevs = netdevs(iface = args.iface)
for dev in netdevs.keys():
print('{0}: {1} MiB {2} MiB'.format(dev, netdevs[dev].rx, netdevs[dev].tx))
Если выполненить программу без каких-либо аргументов, он ведет себя точно так, как раньше. Однако, вы можете указать имя сетевого интерфейса, и посмотреть, что получится. Например:
$ ./net_devs_2.py
em1: 0.0 MiB 0.0 MiB
wlan0: 146.099492073 MiB 12.9737148285 MiB
virbr1: 0.0 MiB 0.0 MiB
virbr1-nic: 0.0 MiB 0.0 MiB
$ ./net_devs_2.py --help
usage: net_devs_2.py [-h] [-i IFACE]
Network Interface Usage Monitor
optional arguments:
-h, --help show this help message and exit
-i IFACE, --interface IFACE
Network interface
$ ./net_devs_2.py -i wlan0
wlan0: 146.100307465 MiB 12.9777050018 MiB
Делаем наши скрипты доступными на системном уровне
С помощью этой статьи, вы можете написать один или несколько полезных для себя скриптов. Конечно, было бы неплохо, если бы вы могли использовать их в любой момент, как любой другоую команду Linux. Самый простой способ добиться этого - сделать скрипт исполняемым и настроить в Bash-alias для нашего скрипта. Можно также удалить расширение файла '.py' и поместить файл скрипта в стандартный каталог для исполняемых файлов пользователя, например, /usr/local/sbin.
Другие полезные модули стандартной библиотеки
Помимо модулей стандартной библиотеки, которые мы уже рассмотрели в этой статье, существует ряд других модулей, которые могут оказаться вам полезны: subprocess, ConfigParser, readline and curses.
Источник: echorand.me